NOIP2023考前必看
前言
在 NOIP2023 前一周,想起来能够稍微写一点文字,用来给自己以及别人在考试前最后一刻用以提示或警醒。以下内容以我个人及身边的人的血泪经历以及网上的一些资料整理而成。
一、关于编译
编译不过,是最愚蠢的错误。但是由于大家的机器与评测机或多或少有差异,所以建议采取一些措施避免最后评测时出现编译错误。同时,我们可以通过一些特殊的编译选项来调试问题。
1.编译选项中加上-Wall -Wextra,这两条非常建议加上,有的时候,警告即错误,对于一些很无脑的错误可以直接通过警告发现,常见的如"Unused variable 'n'"(表示变量 n 未被使用,说明你可能没读入之类的,也有可能你有个变量压根没用),有的精度问题也会直接给你报出来,这样子的话可以防止int,long long混用导致的精度丢失。(CSP2022 中 wyf 的错误是可以通过开这个避免的)
2.不建议加上-Werror或-Wfatal,这个表示遇到警告就视作错误停止编译。但是警告不是所有的都要避免掉,比如我们使用的循环变量通常是int(正常人不怎么会用size_t的),那么这个和字符串等的size()函数比较时会有一个 Warning,但是这个 Warning 通常是无伤大雅的,不用去管他。
3.在 Windows 下加上-fno-ms-extensions。微软经常会搞一些花里胡哨的拓展,比如一个函数如果既没有返回类型声明又没有返回值,那么 Win 下默认不会给你报错,但是一放到评测机的 NOI Linux 下就炸,就是没加这个选项的缘故。(CSP2023 中 yhs 的问题可以通过这条避免)
4.在 Linux 下加上-fsanitize=address。这个是编译时加上了一个运行时错误检查器,如果运行时出现了错误,那么它会为你直接指出问题位置,可以用来调很多 RE 以及潜在 RE 的问题。Windows 下可能可以用,但是貌似会缺一个库。
5.加上语言限定-std=c++14,这个是按照 CCF 官方的要求,如果不用 Dev-C++那么配置编译时建议用这个,用 Dev-C++的话打开 ISO C++ 11 也就够了,C++11 和 C++14 差距不大。
6.如果需要调试,请加上-g -Og,如果需要测试性能,请加上-O2(两个不能一起用)
7.不要使用如register之类的早期编译器提示类型,现代编译器不在乎这个,而且写了可能会 CE(如果以后 CCF 用 C++17 了)
8.#include<bits/stdc++.h>中的/打成\在 Win 下可能不会报错。
9.注意内存,可以在程序某个位置加上system("pause");将程序暂停,然后去任务管理器里面查看内存。(如果使用 Linux 的,直接用 Arbiter 即可)。
10.变量命名尽可能不要使用完整单词,Windows 下的 gcc 部分关键词名字和 Linux 不一样,如果using namespace std;后可能会导致命名冲突。
二、关于代码
1.文操!文操!文操!文操没加最亏,没处说理去。建议交之前完全按照输入输出文件名测试一下文操没有问题,如果使用 NOI Linux 的,建议自己造几个数据使用 Arbiter 评测一下。(参见 yxh 于 CSP-S2023 的惨痛经历)
2.十年 OI 一场空,不开 long long 见祖宗(反正如果潜在可能爆 int 的全部开 ll)
3.十年 OI 一场空,多测不清见祖宗(参见 ljt 在 NOIP2022 的血泪经历)
4.变量命名尽可能有规律,能换行换行,不要压行,代码可读性非常有利于调试。
5.如果遇到一个很诡异的问题且使用输出法不好弄的时候,两种方法:1.重新写一遍(你之前有一个细节炸了,重写可能就改过来了)2.上 gdb 调试
6.常见的快读的方式是使用cin快读,但是请注意,cin 的快读语句一定要写在文操前面,否则可能出现文件错误。(洛谷用户群里面的说法是这样,建议采纳)
7.分段回答:小数据一个段,特殊数据一个段,大数据一个段。这样子你哪怕任何一个段写错了,也能够最大化得到的分数。
三、关于知识点
一、切忌想复杂,有很多复杂的算法应该是用不到的
二、关于 STL
vector
基本操作用的都比较熟了,但是我要讲几个不常用但有时候可以出奇迹的函数。
1.reserve(size_t size):这个代表 vector 预留好size大小的空间(如果当前空间已经大于size,那么不起作用)。vector 内部的实现原理是这样的:一开始有一个长度为 k 的数组,如果到某一次加入的时候放不下了,就声明一个长度为 2k 的空间,然后将原来的东西拷贝过去,原来的那个数组析构掉,然后继续插入。有的时候,当数据量极速增长时,会出现大量这样的调整操作,从而导致效率下降。这时,我们用reserve()预留好一定的空间,就可以提升性能(这个东西一般是用于把 vector 当栈当中的,作为一个栈,其可能急剧增长,但是总量是有限的,预留好空间可以提升性能。至于你问我为什么不用静态数组,显然的,vector 写起来更舒服)
2.emplace(size_t pos, Args ...):将 Args 就地构造以修改pos位置所对应的值。这里我们要讲一下就地构造的优点。当我们现在有若干个数据的时候,按照传统的下标运算,其操作就是先将独立数据构造成这个类型的一个对象,然后将这个对象拷贝到指定位置。而如果使用emplace(),那么就是在那个指定位置上直接进行构造,可以少一次拷贝操作,减小常数。不过这个东西不要滥用,如果你这个对象无需构造,是一个右值(也就是一个常量,如123,"aaa"等),或者加入的这个东西已经是一个对象了(比如你已经有一个pair<int,int> a了,那么你就不需要构造了,用下标运算拷贝进去就行了),那么就不用这个函数,用传统的下标运算即可。
3.emplace_back(Args ...):道理同上。表示在 vector 末尾插入一个元素。
4.resize(size_t size):可以调整大小:只保留前size个元素。
stack&queue&deque
个人建议,如果为了代码可阅读性,使用 stack,queue 不妨(尤其是你写 spfa 广搜之类)。其他的,如果有用到栈,最好一律用 vector,用到队列,一律用 deque(因为 vector 和 deque 有迭代器,你可以打出来看)。其中,deque 往前面插入是push_front(),其它和 vector 一样,弹出类推。
list
不建议用,速度慢,既不如手写指针式链表,也不如链式前向星。
map&set&multimap&multiset
这四个都是基于红黑树的极度常用的 container。均支持插入操作insert(x),删除操作erase(x),查询操作find(x)(查询不到就返回末尾迭代器end()),计数操作count(x)(当然,map 中计数只有 0 和 1),二分操作lower_bound(x)&upper_bound(x)&equal_range(x),分别代表求出在排序后序列中不小于 x 的值的迭代器,大于 x 的值的迭代器,相等元素范围。其中,map 支持下标操作,如果下标对应的值不存在那么自动创建。multimap 只支持迭代操作,因为它允许重复元素。set 和 multiset 都支持迭代操作,区别在于后者支持重复元素。
同时,这几个 container 都支持比较运算,所以有的时候可以用他们做一些诡异的题目。
unordered_map&unordered_set
是 STL 的 hash 表,支持下标操作和迭代操作,但是迭代的输出顺序是无序的(这是由原理决定的)。
用法基本同 map(但是没有二分操作),性能高于 map(一般来说)。
bitset
位运算的神器。这个结构是静态的,与前面的 container 不太相同。支持位运算和输入输出符。set(int pos)表示将某位置为 1,reset(int pos)表示将某位置为-1,flip(int pos)表示将某位翻转,size()返回大小,count()返回 1 的数量,test(int pos)返回某一位的值,to_ullong()返回该 bitset 对应的整数值(前提是不会爆),to_string()返回该 bitset 转换成字符串的结果。
algorithm
我列一个清单(都是常用的,在初赛中出现过在复赛中很有用的),不做详细阐述,不会的自己去cppreference上看:reverse() unique() partition() sort() stable_sort() lower_bound() upper_bound() binary_search() equal_range() merge() make_heap() push_heap() pop_heap() max() max_element() min() min_element() minmax() next_permutation() prev_permutation() iota() accumulate()。
三、关于 pb_ds
首先,在施法前需要吟唱一下:
#include<ext/pb_ds/assoc_container.hpp> //所有库的前置
#include<ext/pb_ds/xxx_policy.hpp> //xxx你用什么填什么,可以填tree hash trie
#include<ext/pb_ds/priority_queue.hpp> //更强大的priority_queue
#include<bits/extc++.h> //包含了ext下所有库,不过不推荐使用
using namespace __gnu_pbds; //使用命名空间其中,trie 建议自己写不建议使用 pbds(因为自己写也不复杂),其余的用法如下。
hash_table
cc_hash_table<Type1,Type2> h; //拉链法
gp_hash_table<Type1,Type2> h; //探测法
h.find(key) //返回key对应的迭代器(如果没有返回end())
h.insert(make_pair(key,val)); //插入一个值
h[key]=val; //修改一个值拉链法是同 hash 值用一个链表存储,探测法是某位置如果有冲突就向后找到第一个放得下的位置。由于 Cache 的问题,导致探测法往往快于拉链法,用后者更优秀。
tree
tree 当中只要掌握红黑树的用法即可,因为这个的 Splay 基本没啥用,而这个相比 STL 的 set 多了求第 k 大等操作。
一个 tree 的 declaration 是这样的:tree<data_type, mapping_type, compare, tree_type, update>。其中data_type表示数据类型;mapping_type一般没啥用,设为null_type即可;compare表示排序规则,less<>从小到大,greater从大到小;tree_type表示树的类型,一般用红黑树,是rb_tree_tag;update表示更新方式,可以自己手动定义以维护特殊值,默认为tree_order_statistics_node_update即可。
tree 支持 set 的全部操作,同时支持join()合并操作,lt.split(value,rt)按 value 分裂 lt 和 rt 两棵树,order_of_key(val)求排名,find_by_order(rank)求第 k 大。
heap(priority_queue)
pbds 最有用的堆一般是配对堆pairing_heap_tag和斐波那契堆thin_heap_tag,其复杂度见下图(网图):
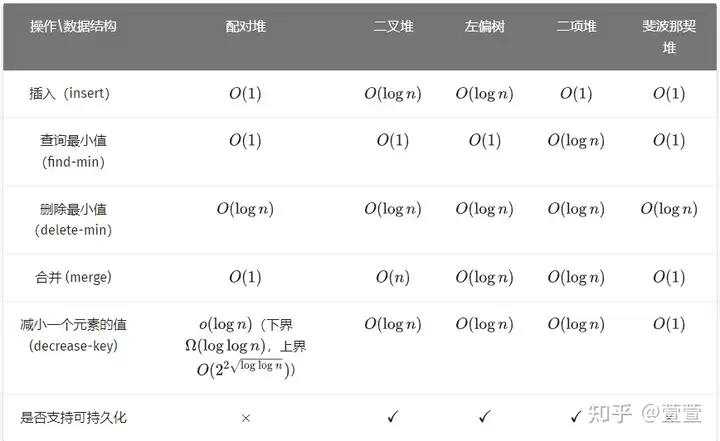
堆的定义可以用前面的 tree 类推,其排序规则与 STL 相同,不过可以使用迭代器(虽然用了意义也不是很大)。
priority_queue<data_type, compare, heap_type> q; //数据类型,比较规则,堆类型(如上面的xxx_tag)四、关于卡常
1.能够使用短小的数据类型不要使用长数据类型(也就是能用int不要用long long)。写过汇编的都知道,Intel 的 CPU 内部寄存器可以分段使用的,如果使用long long这个 64 位类型,那么一个值就会占满整个寄存器;而如果使用int这个 32 位类型,那么一个寄存器就可以放两个int(分别放高 32 位和低 32 位)。正是这个原因,所以越短的数据类型其能够在寄存器占据的个数更多,速度也相应更快。(请注意,这条是在满足 2.2 的前提下使用的)
2.能够使用数组等连续数据结构不要使用链表(手动链表,链式前向星另当别论)。连续数据结构可以被载入 CPU 的 Cache 中,高速用于后续计算,而链表就会导致数据的散乱,无法 Cache 优化。
3.手写快读快输。根据经验,手写的快读仍然比关流的 cin 快不少。
4.能不用 STL 不用 STL(尤其是array就不该用,vector如果没有动态需求不建议用)。STL 虽说开了 O2 不慢,但是由于 STL 需要考虑很多特殊情况,导致跟原始数据结构比他也不快。但是,如果是算法之类的,STL 里面直接有的,且复杂度正确的(如sort()),那么最好用 STL,毕竟你不一定能够写出比他们强的代码。(虽说 STL 要考虑特殊情况会慢一点,不过影响有限)